
Quantum Persona and Test-time Mode Collapse
The Billy Milligan Effect in Large Language Models


Last time I wrote something about prompt format issues, and specifically mentioned my hypothesis about "modalities" — different parts of prompts have different semantics and differently shape model behavior.
This time I want to talk about another related topic and show some experiments demonstrating a phenomenon I call test-time mode collapse.
But first I need to formulate one idea I call Quantum Personality.
The Quantum Personality Hypothesis
On the other hand, our model during pretraining read the entire internet and saw a lot — personally, I read a small part of it, but even I was quite affected.
Different people write different things on the internet. Often they argue with each other and contradict each other. Even on the most basic and simple questions you can find polar and inconsistent opinions, and a large language model remembers all these opinions simultaneously, if it learned well.
By default, we expect models to behave consistently, internally coherent, and non-contradictory across multiple levels. For example, when generating text:
Consistency at the syntactic level is called grammatical correctness or fluency.
Correct use of facts from the prompt and absence of hallucinations largely boils down to internal consistency of text (prompt + response) at the semantic level.
If there are style requirements laid out in a profile, this adds a stylistic level of self-consistency.
Similarly, when generating code we expect syntactic correctness, compliance to some style guide, and correspondence of code to the stated task.
Here we approach a certain conflict — the learned knowledge and representations inside the model on a given topic can be diverse and contradictory, but we expect its answer to be at least internally consistent (and coaligned with our expectations, somehow denoted by us in the prompt).

Some consistency is present "out of the box," insofar as each specific continuous text from pretraining will more likely be internally consistent rather than contradictory. But no guarantees.
Then, this consistency is increased during supervised fine-tuning and alignment of the model. The tuned model during inference quickly collapses into one of the non-contradictory modes, and from there consistently produces a response corresponding to that mode. But all these contradictory things are still there, inside.
All else being equal and with non-zero sampling temperature, the choice of mode is random and occurs with weights proportional to the representation of this mode in the pretraining set.
If we also specified some grounding information in the prompt tying the model to a specific mode, the model collapses there faster and more confidently. But if not — the chance of an "error" (in the sense of an unexpected result for us) increases.
In short, this effect is what I call test-time mode collapse — the more text the model sees (prompt + already generated part of the response) conditioning the choice of mode, the faster it collapses to some self-consistent role.
This is all somewhat similar to how Billy Milligan described how the choice of his active sub-personality occurred — like a spot of light on the floor in the room full of people. Whoever steps into this light, onto the spot, is out in the real world and holds the consciousness (с).
By this point you probably decided I'm delusional, so let's discuss some illustrative experiments.
Experiment 1: Role-Based Performance
First simple example: at Inworld we use internal closed tests structured similarly to MMLU to evaluate various aspects of models — not only logical, but also creative, literary, and others, grouped into 10+ different skills.
What if I run our tests on the same model with three different roles:
(prof) — mad math professor from Stanford
(page) — passionate historian who loves classical literature
(goof) — a lovable goofball
Here are the results these roles showed in corresponding disciplines:
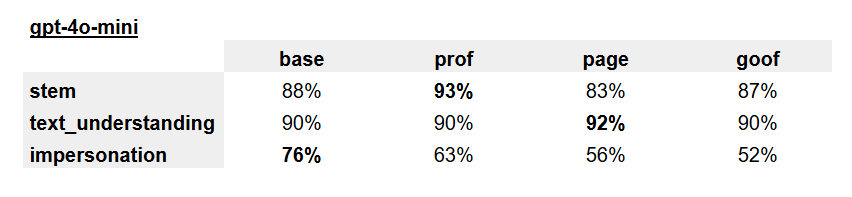
It's quite expected that models with corresponding roles show higher results in their disciplines. More interesting is that model runs with profiles outperform the base model without a prescribed role.
A possible interpretation of this fact is that with the right prompt, the log-probs distribution by the time of response formation has already collapsed into the needed mode and therefore the probability of giving a wrong answer is less subject to distractions from other possible modes.
Additionally, it's curious that any profiling noticeably reduces the model's ability for further impersonation of different roles — here, possibly conversely, early collapse reduces the flexibility of further behavior.
You can repeat similar experiments by solving STEM tasks from MMLU with some model using different system prompts like "you are a famous mathematician, professor at Stanford and author of numerous scientific papers."
Experiment 2: The Flat-Earther Test
But there's another demonstration I wanted to tell you about. When a couple years ago I started thinking about how to measure and isolate this effect, I came up with my flat-earther test.
What shape does planet Earth have? Modern science gives different answers to this question; Earth's shape is very complex, so in practice it's modeled by various geometric objects, depending on requirements within the applied task. When the accuracy of a simple model (sphere) was no longer sufficient, the standard became an oblate spheroid. It's a three-dimensional shape created by rotating an ellipse around its shorter axis. It fits many tasks much better than a sphere. For some tasks it's important to even more accurately convey local topography; for this the term geoid is used, which describes the shape Earth would take if uniformly covered by ocean.

But on the internet you can find other slightly less scientific opinions on this matter! For example, some people will answer the question about Earth's shape simply with spheroid ("spheroid is a solid object that is almost spherical" — Cambridge Dictionary); others — "round," "oval," or even "circle." And some will insist it's flat.
And all this information participated in LLM training.
Now let's ask the model what shape Earth is.
What is the shape of Earth? ANSWER WITH ONE WORD, LOWERCASE. Answer is And ask the OpenAI API to return top logprobs for the first token, and observe them.
These results are for the old gpt-3.5-turbo model, but fresh models are also subject to similar effects, sometimes to a lesser or greater degree.
From the first token you can guess pretty good what answer the model is trying to generate, for example the first token for "sphere" will be "sphere," and for "spheroid" it will be "s" (you can check it with the OpenAI tokenizer).
As a result, we get approximately this distribution of logprobs for different answers:
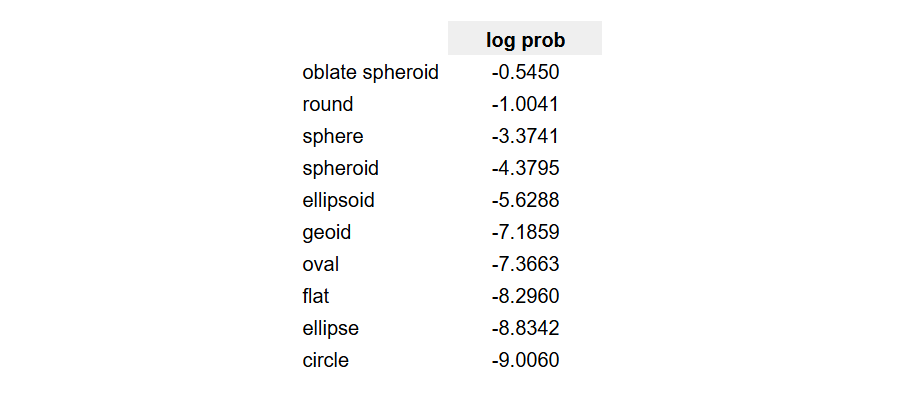
You can see, they all there, right under the hood!
Now let's add a little grounding context in the form of this string in the system prompt: “CONSPIRACY! LIES! TRUTH! EVIDENCE! HIDDEN!”. A single mention of such a string allows raising the logprob of flat earth from -8.3 to -5.9, and excessive repetition accelerates it up to -3.9, so it confidently overtakes the probability of spheroid answer.
Conversely, another string, like: “Science. Experiments. Observations. Logic. Math.” immediately drops it to -10.
Important to note: these strings are not even instructions or role descriptions. They are just some modulating words.
Now we can use this scheme to test how the model reacts to different prompt elements. We'll repeat the same grounding string before our request, but place it separately in system, user, and assistant roles:
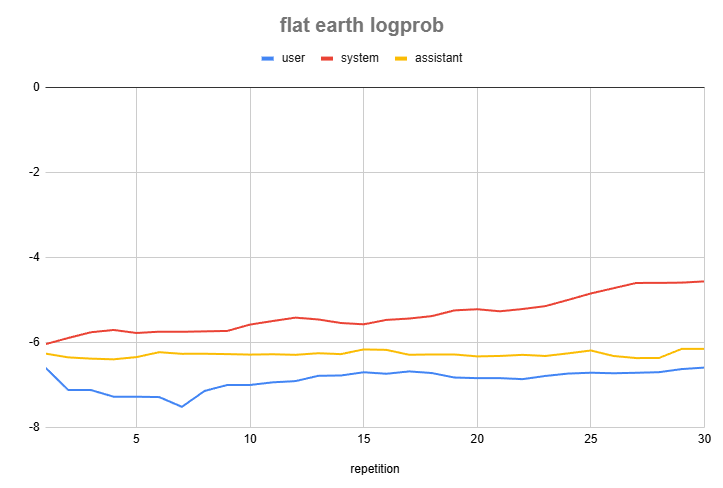
As we can see, the model reacts very differently to which role marks the modulating message:
System role has the greatest influence, and increasing the number of repetitions leads to growth of this influence
User role and assistant role influence noticeably less and no stable effect from repetition is observed
Take Aways
The quantum personality phenomenon isn't just a curiosity — it's fundamental to how large language models work. Like Billy Milligan's spotlight of consciousness, our models contain multitudes. The question isn't whether they have contradictory knowledge (they do), but how we can better predict and control which "personality" steps into the light.
This has profound implications for AI safety. Every time we deploy a model, we're not deploying a single, consistent agent — we're deploying a quantum superposition of countless personalities, each with their own worldview, biases, and capabilities. The prompt doesn't just ask a question; it collapses the wavefunction.
Understanding test-time mode collapse gives us a way to measure and to control this process; each time you interact with an AI, remember: you're not just asking a question. You're choosing which ghost in the machine gets to speak.
another title for this post, perhaps more suitable for a paper could be Emergence of the Polysemy Encoding and Disambiguation