
What's Wrong with TTS Evaluation
There is no one sane TTS quality score, and that has stopped being inconvenient and started being the whole problem.

Modern TTS systems are good enough on simple prompts so the old good metrics no longer point in any clear direction. The interesting failures live in the tails: latency tricks, alphanumericals, long-form drift, voice identity, multilingual behavior, controllability, weird artifacts, customer-specific phrasings. So evaluation has been quietly fragmenting into task-specific protocols.
That is not a crisis. It just means we have to stop asking “which TTS is best?” and start asking the more annoying question: best for what exactly?
Intro
Besides other things, I am the Head of Evaluations at Inworld AI, where we also build TTS models. Our previous TTS model got a friendly mention in a Google post recently. This week we shipped a new one, Realtime TTS-2.
To make any of that actually move, we spent the last half year building a proper TTS evaluation system internally. Somewhere in the middle of that work I realized I had accumulated a mildly unhealthy amount of opinions about TTS eval. When I sat down to write them out, it turned out there was enough material for a semester of TTS Evaluation 101. I do not currently have time to teach such a course, so this is just the pilot post. We will see if it survives a single seating.
TTS Eval Is Following The Path LLM Eval Took
About three years ago I wrote a paper about the inevitable mess that was about to come for LLM evaluation. That paper aged reasonably well. The interesting thing now is watching TTS walk almost the same route, just two+ years late.
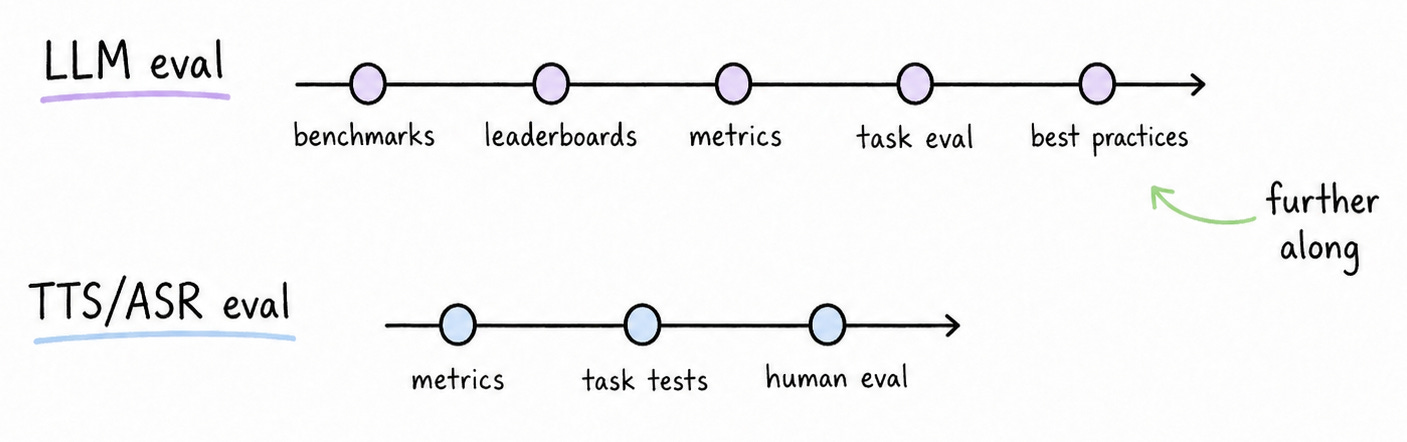
We already have a pile of metrics. We have a few old academic benchmarks. We have a couple of public leaderboards. We have new public claims about things like listenability, controllability, naturalness, and expressivity. What we still mostly do not have is a clean public standard for reproducible end-to-end evaluation, so every serious team ends up reinventing a lot of the tooling.
That creates a familiar situation. Imagine a company claims that its model has the highest listenability. Should we believe it? How is that listenability score computed? On what prompts? In which languages? What does the score mean operationally?
You can already see the field splitting in public. Cresta breaks “good” into accuracy, stability, naturalness, and professionalism, and runs blind panels on top. Hume leans hard into listenability studies and human feedback as a service. Google’s Gemini 3.1 Flash TTS push leads with controllability and audio tags, not generic quality. Fish Audio published blind A/B results on real production traffic with explicit caveats around traffic mix and feature parity. These are all legitimate angles. They are also not the same angle.
There is an old line about the samurai having no goal, only a path. TTS evaluation works the same way. The path depends entirely on why you are evaluating in the first place.
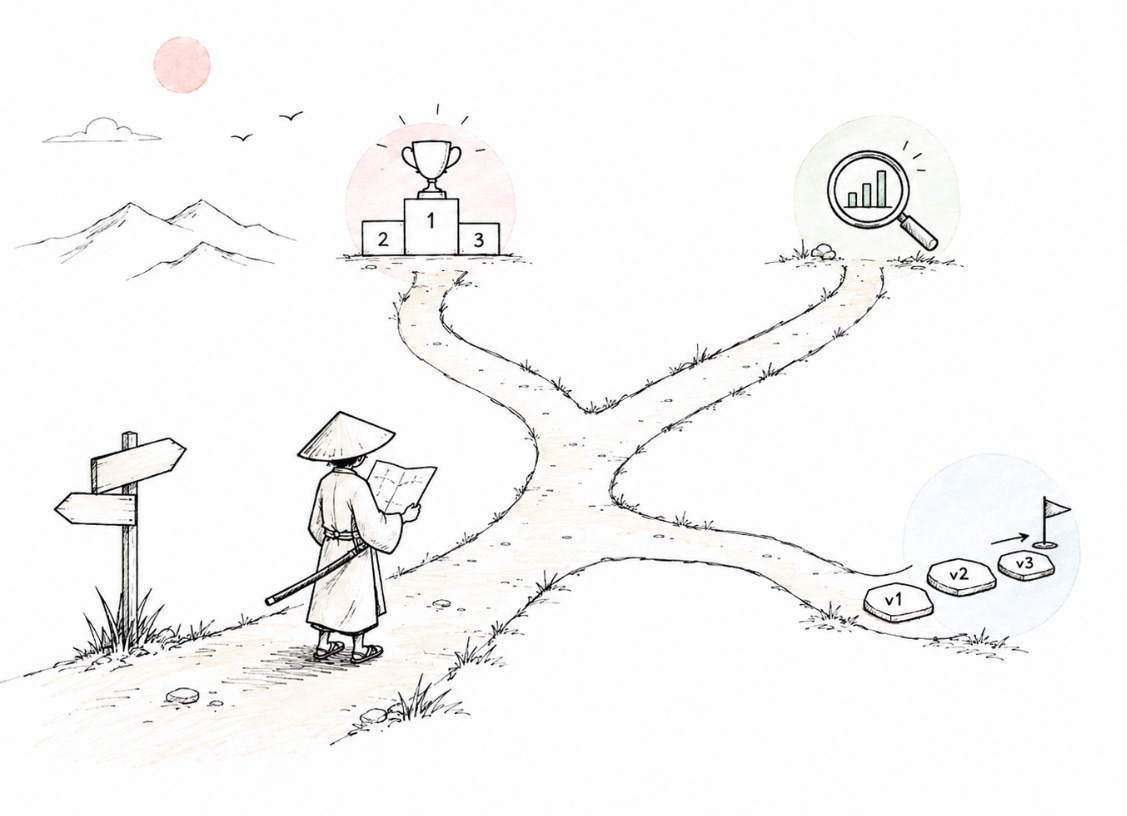
Are you trying to choose a release candidate? Compare against competitors? Find growth points? Track progress version to version? Debug a customer escalation? Pick the best prompt for instant voice cloning? Different decisions, different protocols.
Still, it is easier to start from the boring stuff: price, latency, accuracy. Price is easy. Latency and accuracy are not.
What Is Wrong With Latency
Take an online TTS API. What exactly should we measure to understand how fast it is?
Time to first byte? Then the service is incentivized to immediately stream silence. Great benchmark number, terrible user experience.
Time to end of audio for a fixed text? Then the fastest voice wins, which is not the same thing as the best realtime experience. A model can sound rushed, unnatural, or just speedrun the prompt.
What we actually wanted was a more annoying but more defensible quantity: time to first sound. Not first byte, not total duration, but the moment the user actually starts hearing speech. BTW, we published code so anyone can measure it themselves, instead of trusting our marketing chart. I am not going to retell it here. There is a video with Cale who does it better:
Latency is a nice opening example because it looks objective simple until you try to define it precisely.
What Is Wrong With WER
Historically, Word Error Rate became one of the default metrics for speech accuracy in both ASR and TTS. The original framing comes out of work like the IBM paper on decoding for channels with insertions, deletions, and substitutions.
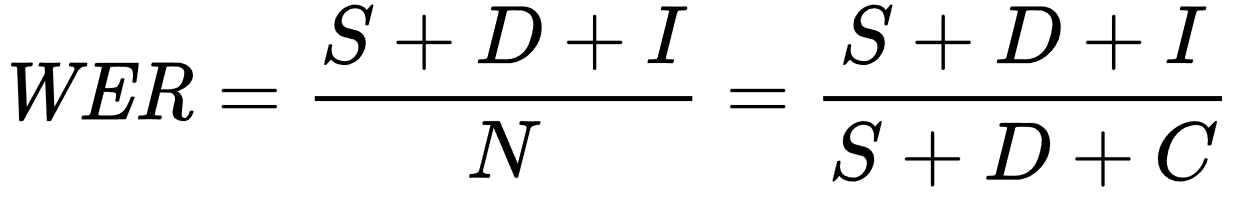
The premise is simple. Synthesize text into audio, transcribe the audio back into text, compare the two. If they differ, something probably went wrong. WER counts how often. This WER is useful in the way old reliable metrics usually are: useful, popular, and full of small traps.
First, despite the name, WER is not constrained to [0, 1]. In the wild it can exceed 100% and keep going. That alone is not fatal, but it is a good reminder that the metric is more operational than intuitive.
Second, it overweights short texts. One wrong word in a 5-word sentence costs 20%. The same one-word error in a 20-word sentence costs 5%. Three extra words in a 3-word sentence -- 200%. So the prompt distribution matters a lot, and “the dataset” stops being a boring implementation detail and becomes part of the claim itself.
There is good news here: there are public benchmarks like SeedTTS-eval.
The bad news is that benchmarks of this kind are starting to saturate. ElevenLabs’s previous model already lands below ~1.5% on SeedTTS-eval in public reporting, and several of the latest providers come in lower than that.
Once strong commercial systems are this close to the floor, evaluator noise is no longer a rounding error. It is part of the result.
Then there is the cross-lingual problem. WER is defined over written words. But words are not comparable across languages in any clean way. Morphology is different. Typical word length is different. The mapping from sound to writing is different. So you cannot meaningfully compare English WER and, say, Turkish WER and conclude “this model is better at English than Turkish” just from the numbers.
People patch this with CER, PER, phonetic alignment metrics, weighted variants, and other dirty hacks. They each answer slightly different questions. None of them gives you a magical north-star number, which is unfortunate, because management would really prefer to have one.
And then there is the obvious operational issue: to compute WER at scale you need a transcript of the generated audio. In practice that means ASR. Any ASR introduces error, even the most recent expensive Gemini models. And when you are looking at WER below ~1.5%, that evaluator noise stops being background and starts being part of the signal.
Worse, the noise is not unbiased. Modern ASR systems often struggle more on shorter utterances because there is less context. That is exactly the regime where WER is most sensitive in the first place.
And even if you somehow had perfect ASR, you would still hit normalization. Text-to-speech and speech-to-text are both many-to-many. 7-11 could be “seven eleven”, “seven minus eleven”, or “seven dash eleven” depending on context. Normalization exists to handle that. It also deserves its own post, so I am going to skip it for now.
So: imagine we somehow got accuracy perfect. Is that enough? It is not, because some voices people simply like more than others. Which takes us to MOS (mean opinion score).
What Is Wrong With MOS
MOS-like metrics are based on human ratings under some protocol, on five-point scales, with the responses collapsed into a single number.
That makes MOS expensive, slow, and subjective, but it also makes it hard to replace. If you want to know whether people prefer one audio sample to another, asking people is still a surprisingly good idea.
Troubles start when one number gets treated as universal truth. The protocol matters a lot. Blind or not? Same text or different text? Randomized order? How many raters? Which languages? Which playback setup? Once you take those questions seriously, “our MOS is higher” becomes much less informative than it sounds in a launch tweet.
Then, because manual rating is expensive, people train learned judges on top of those labels: DNSMOS, UTMOS, NISQA, and so on.
These are useful, and they are cheaper than calling an actual human. They are also often hard to interpret. If one model gets Coloration 3.5 + Noisiness 3.3 and another gets Coloration 3.3 + Noisiness 3.5, which is better?
Spoiler: across most of my own tests, NISQAv2 Coloration correlates with human preference better than I expected. That is nice. It is still not a silver bullet.
Also, these models can also behave very strangely out of distribution. How should a MOS predictor score a cartoon voice? A robot voice? A heavily stylized narrator? Was Vietnamese in the training data? Any tonal language at all? Usually we do not know.
So yes, human eval remains the gold standard, but only when it is a real protocol.
Many Aspects, Lack of Definitions
Of course we trained our own evaluators too.
Expressiveness, arousal (what exactly is the difference?), naturalness, emotions, non-verbals, uptalk score, you name it.
At one point we built four different metrics for conversationality before realizing the actual problem was that we had never agreed on what conversationality meant.
Ronny Kohavi once put it neatly: Once you pick a metric, don’t forget to make sure you all agree on whether you want it to go up or down.
That sounds like a joke until you try to operationalize voice style.
Do we really want high expressiveness? For a game character or a narrator, maybe. For a support-line assistant handling a billing dispute, probably not. Do we want non-verbals, warmth, and uptalk? Or do we actually want something formal, stable, and slightly boring?
This is one reason I do not fully trust public TTS leaderboards as a single answer. Artificial Analysis already does something better than a flat ranking by splitting contexts into four categories: knowledge sharing, assistants, entertainment, and customer service. That is directionally correct.
I think the true category count should be several times larger. And inside each of them you have your own subjective requirements that you have to specify before you can model them, and then model them before you can evaluate them.
Voice Cloning Adds Another Axis
Wait, we forgot something.
So far I have mostly talked as if we pick a single voice and evaluate it. But modern TTS systems usually offer instant voice cloning.
That changes the problem in two ways.
First, you now have to evaluate the system on an input audio sample you do not control or even know in advance. It can be short, noisy, clipped, badly recorded, over-compressed, or just not very representative of the target voice.
Second, you now need to measure similarity to the original speaker. The lineage of that question goes back to speaker identification / recognition / verification tasks.
The standard solution is an embedding model that turns a voice sample into a fixed-length vector. Close vectors mean similar voices, so you can score similarity by distance in that space.
Of course, there are many such embedding families, and they all behave a little differently: x-vectors, i-vectors, wavLM-based, wav2vec-based, ECAPA-TDNN, …
Spoiler: in our own tests, ECAPA-TDNN turned out to be very decent, at least for European languages.
But even after you solve speaker similarity, the optimization target is not clean. Past some point, pushing similarity harder starts degrading expressiveness. So you go from “maximize one number” to “choose between dimensions” again.
Voice Direction Resets The Whole Problem
Let’s add one more dimension.
Our new model Realtime TTS-2 now accepts inline directions like [speak sadly, as if something bad just happened] or [whisper softly, intimate and close-mic, as if not to wake someone in the next room].
What does that do to evaluation? Right. Start over. Define the problem space. Build new datasets, design new metrics.
Are all voices equally steerable? Of course not. Can the same voice be highly steerable along one axis and stubborn along another, like speed, pitch, affect, intensity, whisperiness? Of course yes. Do we even know the full list of directions we care about? Naturally, no.
So What?
This is the part where I stop complaining and try to be constructive. My current view, in nine somewhat opinionated points:
There is no single quality score. TTS evaluation has split into task-specific evaluations.
Automatic metrics should be a panel: Faithfulness, identity, intonation, artifact metrics, latency, quality aspects, controllability, stability, prompt quality, whatever. Different metrics answer different questions.
Sounds good is not a technical requirement. You have to specify the use case scenario, domain, language, latency and accuracy requirements and dozen other things.
Evaluation should start with the task (target decision). Release gate, competitor benchmark, customer debugging, prompt scoring, checkpoint selection. Different decisions, different protocols. If you start from “which metrics can we run?”, you get a dashboard, and the bad one. If you start from “which decision do we need to make?”, you get an evaluation.
Public leaderboards are useful, but they are not ground truth. They depend on prompt and audience distribution, supported features, and a long list of methodology caveats. Great signals. Not revelation.
Dataset is the contract. No long-form in the dataset means you cannot really claim long-form quality. No customer prompts means the eval can be pretty and useless at the same time. No multilingual or code-switch data means your “70+ languages” story is probably underdetermined.
Human eval is still the gold standard, but only as a real protocol. Blind. Matched text. Randomized order. Enough raters. Confidence intervals. Proper math.
TTS eval is a process. It looks something like: task → dataset → metrics → calibration → auto eval → human review → decision.
This all is much less tweetable than “our model is #1”. It is also much closer to reality.
What I Left Out
This post is already huge, so a lot of material did not fit:
normalization,
finding specific failure modes and building metrics for them,
designing datasets to increase metric sensitivity,
alphanumeric control,
multilingual vs cross-lingual evaluation,
long-form-specific breakdowns,
prompt-cooking issues in voice cloning,
evaluator calibration and false-positive management,
multimodal LLMs as judges,
turning repeated customer complaints into canonical benchmark cases.
All of that deserves separate posts. Tell me in the comments which one to write next.
Outtro
We had two speaker similarity scores, eight alignment-based metrics, twelve types of hallucination detectors, a tail-click catcher, and a whole galaxy of acoustic features. Also an expressiveness score, an arousal score, a WER family, and five nisqa_v2 metrics. Not that we needed all that for the evaluation, but once you get locked into a serious TTS project, the tendency is to push it as far as you can. The only thing that really worried me was the vowel prolongation rate.
That is the high-level picture, without most of the dirty details.
And yes: a post about TTS without a single sound would be a bit suspicious.
So here is a robot singing in a cathedral about TTS evaluation: