
What's Wrong with Chat-Templates Format for LLM
This is going to be a long read (I rarely write these), but I believe it's a useful and interesting one with some non-trivial twists along the way. Chat-templates are broken, and I'll explain why.


In this post, I’d like to discuss the current situation with LLM prompting standards and how we got into this mess.
What makes a good prompt good?
Let’s not hide it — we’re all doing prompting now. And prompting is complex and chaotic, even if we rebrand it as context engineering.
You can discuss and evaluate prompt quality at different levels.
Obviously, good prompts are task-specific. Some tasks require precise instructions, others require diverse examples, and still others require style demonstration or role description.
But prompts are also model-specific. For instance, Anthropic recommends structuring prompt sections as XML tags for their models, while OpenAI suggests using markdown-style formatting. Some experiments show that different models prefer different information sequencing (primacy bias vs recency bias). For example, gpt-3.5-turbo responded better to instructions placed at the beginning of prompts, while llama-2 worked more effectively with information at the end.
Finally, good prompts must account for low-level nuances like effective context window length and static prefix length (important for efficient caching).
It's hard to keep track of all this for even a single prompt. However when dealing with production request flows, you need to automate the process somehow — seamless automatic migration between models, unit and regression testing, and other boring yet necessary tasks. To approach this systematically, I spent quite a bit of time analyzing typical problems in our projects, customer patterns, and various publicly available prompt templates to understand how to bring some order to this chaos.
And here's what I want to say:
Chat-templates aka LLM messages are fundamentally broken in several ways
I should clarify that when I say "broken," I don't mean in the terrible sense of "everything's bad and nothing can be done." Rather, I mean it in the spirit of early internet protocol development — they emerged organically, and now we have various legacy properties we have to live with (read about "referer" etymology) and sometimes can exploit in ways completely unintended (states and sessions over HTTP with ugly hacks like cookies and fragments). The chat-templates story seems similar, and I want to discuss several important flaws I've managed to identify.
There are technical issues, a lot of them. But the most important problem is that they operate simultaneously on several intertwined levels of representation — both technical and logical. This makes it difficult, sometimes impossible, to separate these levels into independent, isolated abstractions (in the spirit of MVC approach) and blocks further development.
But to explain what I mean, I need to briefly describe how this is currently implemented at a practical level. Skip this section if you believe you fully understand this mess.
How Chat Templates Work
At the lowest level, we have technical special tokens of specific base LM models — they exist at the linear text inference level, before the model learns to work in dialogue mode. Usually, these are tokens serving 3 specific roles: beginning of sentence (BOS), end of sentence (EOS), and padding (PAD). Sometimes they're the same tokens, sometimes different. In any case, they're usually well-packaged under the hood and described in files like generation_config.json. This part is fine.
Next, when the model undergoes fine-tuning for dialogue mode, it learns that each prompt is a messages-based sequence where each message is attributed to a role — most commonly system/user/assistant.
Eventually, this sequence must be somehow uniformly represented as a linear text sequence. As far as I remember, this idea was first proposed as the ChatML (markup-language) format by OpenAI's team when fine-tuning ChatGPT over regular GPT.
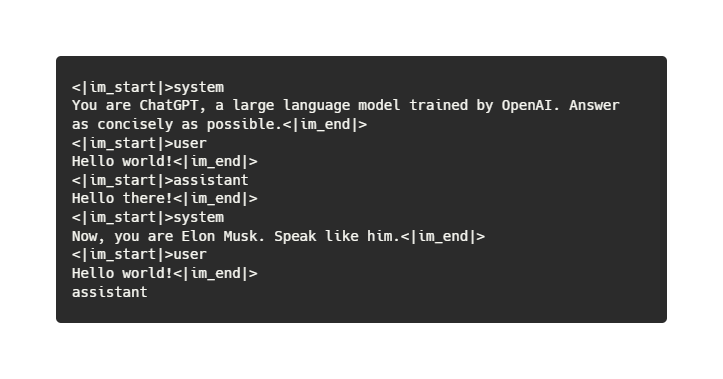
In short, we prefix each message with a header like `<|im_start|>`, then the role name, then a newline and the actual message. At the very end, we put `<|im_end|>`. What could possibly go wrong?
By the way, last time I checked (about a year ago), Azure API still allowed chatting with ChatGPT models at this low level, sometimes called “text completion." You might ask — why would you need this? Well, through the messages interface, it can be tricky to get logprobs for non-first tokens in a message.
Finally, according to the general plan, a prompt engineer comes and breaks down their business logic into such a sequence of messages. And here everything seemed simple.
If it's a friendly chatbot, you first write a system message about it being a friendly chatbot, then show the history of previous messages, ending with the user's last message. The model then responds friendly as an assistant.
Or if you have a task for solving tricky problems — then you write a system message about the model working as a very smart solver of tricky problems, and here you also give general advice on how to solve such problems. Next, we make a user message with specific task conditions, and the model responds with a solution as an assistant.
This is how it's supposed to work.
The Problems
Now let's talk about the problems.
1. Tag Chaos
First, this ChatML format took root pretty well, but like any good idea, it clearly asked for improvement. Various roles like tool_call and tool_response appeared, along with additional tags for media content and other enhancements.
This would be half the trouble, but even the basic tags didn't really unify. I'm not sure why, but different base model providers decided to use different tags, though it seems this could all be unified at the tokenizer level.
I ran a scraper over popular HuggingFace repos and collected about a hundred chat_template.jinja files, which have recently become standard for describing model requirements for chat message representation at the low level.
A quick analysis reveals several different families (you could do deeper phylogenetic analysis if desired):
Some models, like Qwen, directly inherit ChatML tags, adding their own as needed
Older (pre-4) Llama models use
`<|begin_of_text|>`, `<|start_header_id|>`, `<|end_header_id|>`, `<|eot_id|>`But fourth-generation Llama models switched to a more concise set:
`<|header_start|>`, `<|header_end|>`, `<|eot|>`Gemma family models use
`<start_of_turn>`and`<end_of_turn>`tagsMistral historically prefers different tag syntax, like
`[INST]`, `[/INST]`Phi models embed available roles directly in tags:
`<|system|>`, `<|assistant|>`, `<|user|>`, `<|end|>`Some others do the same, like the Kimi family:
`<|im_system|>`, `<|im_assistant|>`, `<|im_user|>`, `<|im_middle|>`
For a bigger picture, check these examples from llama.cpp. Anyway, you get the idea. If you have other amusing examples, send them in the comments.

I even didn’t start talking about tool using (pretty chaotic set of implementations), thinking process (why it’s not an another role?) or multi-modal data. Life is too short.
2. Zoo of Roles and Messages
So far this doesn't look like a big deal — after all, with effort, you can write an automatic translator between two given formats. Right? Right?
Turns out, not really. The sequence of roles in messages can't necessarily be arbitrary, and these constraints are model-specific.
Let's start with well-known facts:
OpenAI models allow arbitrary sequences of system/user/assistant messages.
Gemini requires at most one system message (and if present, it must be first); then you can alternate user and assistant arbitrarily.
Anthropic API, conversely, requires at most one system message (and if present, it must be first); alternating is enforced — consecutive same-role messages are merged by API into user→assistant→user→assistant… sequence.
With open models, it's even more fun:
Qwen gives full freedom in role alternation.
Gemma 3 scheme requires strict user/assistant message alternation, but it embeds system just into the first user message, so there is no system message really.
SmolLM3 scheme allows arbitrary system messages, but ignores all except the first.
So, generally, if we want a universal (cross-model compatible) scheme, we should stick to the strict sequence: [system,](user,assistant,)*user
Well, we can work with that.
3. Jinja Hell
By some ridiculous coincidence, jinja has become the de facto standard for writing dynamic prompt templates. It's hard to add anything here. If you've ever tried testing a complex Jinja template for errors — you know what I'm talking about. A syntactically rich interpreted language without explicit typing or proper exception handling or unit testing tools. Here's an illustrative thread from Stack Overflow, 8 years ago, long before the LLM boom.
You never know on which input it will crash. There is nothing in the world more helpless and irresponsible and depraved than a man in the depths of a jinja template debugging.
4. Tangled Abstraction Levels
But still — remember I said above that the main problem, in my view, is tangled abstraction levels? Here's what I mean.
Say we have a chatbot — it's logical to put the persona description in a system message and keep history as alternating user and assistant messages. Logical. Until we hit the context window size limit. Then we're forced to somehow shorten the history. Leading technologists recommend summarizing the history, and suppose we do that. Where do we put the summary? In the first system prompt as part of the persona description? In the first user message — as a retelling of the previous conversation? What if we have a three-person conversation — two users and one assistant? Shall we merge both users together?
Or say we have a task-solving request. And we have few-shot examples of similar tasks — maybe we put them as user-assistant pairs? But what if they bias the model's real responses (since it will rely on them as real preceding dialogue)?
It seems simpler to stuff everything into one system prompt, breaking it into blocks inside at your discretion. What a useful abstraction that was.
5. Modality Identification and Isolation
What difference does it make where to put instructions, especially if we don't have a pure chat pattern? Here interesting questions arise, somewhat echoing the fascinating post about the waluigi effect. Everything what follows here is some speculation of mine that can and should be tested experimentally (we're working on this). Until then, these are my abstract thoughts.
What we put in system messages becomes objective reality for the model — foundational and allowing it to choose from multiple roles and behavior models learned from pretraining. For it, this is the narrator voice, even if it's an unreliable narrator.
What lies in user messages is input information — it may be correct or not, contradictory or not, the user may be friendly or not (especially if we're modeling a game character).
What lies in the assistant's previous messages is primarily a context and also maybe communication style example, while the model itself may consider the information in them unreliable, for example if the system prescribes dishonesty with the user.
Homework: Try solving some MMLU problems by presenting tasks in system vs user roles and compare results.
All this leads to the thought that we historically latched onto the chat messages format, but it constrains us quite strongly, even when creating dialogue characters. Ultimately, at the bottom level, it's just text where we've assigned additional modality (as I call it) to arbitrary sections.
But these modalities aren't strict, hence the effectiveness of jailbreaks working mainly through reframing. If you put a summary of previous chat turns into the system message, could a malicious user poison it to make a jailbreak? This kind of questions largely echoes criticism of Von Neumann architecture, where code and data lie in shared memory, leading to many errors and vulnerabilities.
Here are simple examples we at Inworld encountered several times in practice: we describe a character profile and have examples of this character's dialogue style; but if we put them in a system message, the model might use facts from them as ground truth and often repeat them in conversation. Repetition is a standard issue with dialogue models, and we often want to reduce their probability. We do it with fine-tuning, and suddenly we lost knowledge/fact utilization — since we taught the model to ignore facts from the prompt. In the end, a good solution often involves defining a task-specific semantic structure corresponding to your needs (section X is about style but not facts, section Y is about facts but not style, this is about the user, and this is external information from them that absolutely cannot be trusted) and reinforcing this structure with fine-tuning.
Long story short, for now, it seems these blocks haven't fully crystallized for us into a universal flexible structure, while the system/user/assistant scheme is too much of a leaky abstraction to stretch over every task.
Living with This (Takeaways)
Someday, we'll definitely bring order to all this. But for now, we need to learn to live with it as it is. My short takeaways for now:
Keep it simple — my choice is a system+user message pair. It is supported by almost all the models (hello, Gemma!), so your solution will be portable.
If you have several specific blocks with different semantics (assistant profile, instructions, examples, user input, …) and you can fine-tune your model — spend some time on developing a synthetic dataset to teach the model how to work with your data. It gives you much more stable and controllable setup.
If you use jinja (or similar, like njk) templates, do tests. Seriously, spend some time writing regression and unit tests, it will save a lot of your time later.
But I feel like I made you sad. Please, don’t, it’s not so bad after all! I have a couple of ideas about how to fix it, and I’ll try to share my solutions soon. Meanwhile, please share your opinions, interesting cases, and critiques in the comments below!