


HUMOR ARENA
TLDR: we made HUMOR ARENA, a site where you can participate in side-by-side labeling of various generated one-liners, see the ranking of models, and read the automatic top of generated jokes.

Main link: HUMOR ARENA website
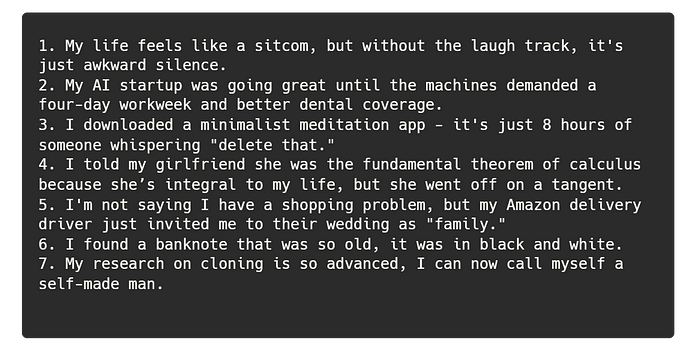
Quick quiz: of these 7 one-liners, only 3 are human-written. Can you guess which ones?
Anyone who has asked an LLM to make a joke knows how bad the results usually are. Usually, it responds with one of the memorized standard dad jokes (Why did the scarecrow win an award?.. Why did the tomato turn red?.. Why don’t scientists trust atoms?..). (Jentzsch and Kersting 2023) show that over 90% of the 1000+ jokes generated by ChatGPT were the same 25 memorized jokes.
Does this mean that modern models are basically incapable of generating a good joke, or is the problem that we are not explaining the task well enough? A good joke should be original, but in the training data, models can only see old jokes, and the better the joke, the more copies of it are likely to be encountered. What if we isolate this signal and only consider original, new, unique jokes? How can we decide which joke is funnier?
A successful joke is often based on some pattern, such as a broken expectations, pun, or a play on words. (Warren, Barsky, and McGraw 2021) refer to more than 20 distinct humor theories attempting to explain humor appreciation. Indeed, the success of a joke also depends on context and audience. If two well-known popular standup comedians switch texts, it is likely that the audiences of both of them will be disappointed. There are psychological studies showing the polarization of audiences according to different types of perceived humor (Thanks to Pavel Braslavski for discussions and advice on this topic). Long story short, there are workshops, conferences, valious research on these questions, but no one knows exactly how it works.
Earlier this year, my colleague from Inworld.AI, Pavel Shtykovskiy, and I decided to apply a data-driven approach to this problem. Taking a dataset of one-liners labeled by a large number of people with pairwise ratings (which of two jokes is funnier), we tried to reconstruct the set of rules behind the determination of the better joke, the so-called humor policy.
We then introduced a multi-step reasoning scheme with generation and consequent refinement of associations to generate novel one-liners on a given topic.
As a result, our generated jokes on blind labeling by humans were significantly funnier on blind labeling by humans than a baseline set of good human jokes — for comparisons, we used a subset of the dataset collected by (Weller and Seppi 2019) from Reddit jokes, and filtered based on user’s upvotes.
The results were pretty good to our taste, so we published all the details in our Humor Mechanics paper at The International Conference on Computational Creativity (ICCC) 2024.
After reading our paper, an old friend of mine, Alexey Ivanov from OpenAI, suggested we should create a platform where people can compare jokes generated by different models and thus form a ranking of models by their ability to make people laugh. After spending a few weekends, Alexey and I put together a prototype — Humor Arena. To aggregate pairwise scores into a single rating we used the new evalica library from Dmitry Ustalov (thanks Dmitry!).
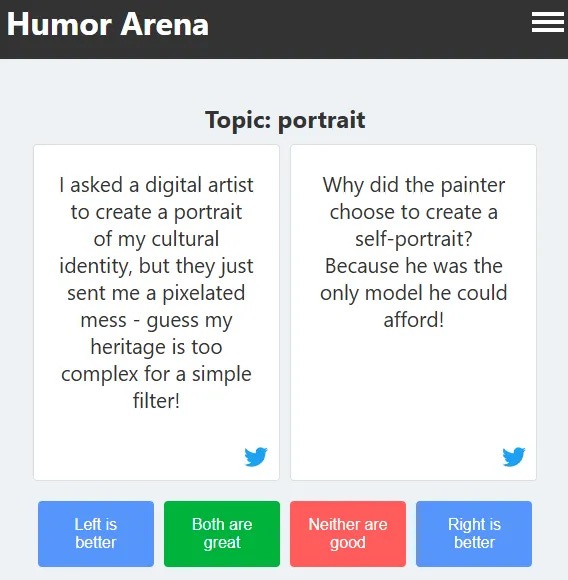
To make the result more interesting, we also invented a way to automatically rank jokes based on the current partial pairwise labels, thus creating a beta version of the automatic top of jokes. The current top seems to be prone to dark humor and self-criticism. We’ll see when more pairwise scores are accumulated and the rankings are recalculated.
And yes, about the 7 jokes at the beginning of the post — 1, 3, 5, and 6 are model-generated, as are all the others — there were no human jokes among those jokes, sorry.