

TLDR: I analyzed 1K+ Reddit posts about AI agent projects, processed them automatically into graphical schemas, and studied them. You can play with them interactively here. Besides many really strange constructions, I found three dominant patterns: chat-with-data (50%), business process automation (25%), and tool-assisted planning (15%). Each has specific requirements and pain points.
A few weeks ago, I got curious about what people are actually building with AI agents in the wild. We do it in Inworld quite a lot lately, so I wondered if we miss something. Not the polished case studies or marketing demos, but the real, messy projects that developers brag or cry about on Reddit.
So I did what any reasonable person would do: I scraped several thousand posts from AI-related subreddits (huge thanks to Project Arctic Shift, free API to reddit data for reseachers), parsed them, and turned them into visual schemas using (of course) the Claude-powered agent.
What I found was both more organized and more chaotic than I expected.
The Reality Check
Before diving in, some important disclaimers:
This data skews toward early adopters and optimistic experimenters, not necessarily profitable businesses.
A Reddit post about a project doesn't mean it works (or even exists.)
Some posts are pretty old. Some posts can be already deleted (but sometimes comments are more interesting.)
Even working projects aren't always accurately described.
Beware of hallucinations and double-check the original posts, since these schemas are fully generated.
Three Classes of AI Agent Projects
Despite the apparent chaos, I found remarkably clear patterns. Three classes cover the majority of all cases, with some overlap but distinct characteristics.
Class 1: Chat-With-Data (approx. 50% of projects)
This is the dominant pattern: a chat interface to interact with domain-specific data via RAG. The data sources vary wildly:
External: Web search results, Wikipedia, news feeds.
Internal: Company databases, university course materials, D&D lore.
Ephemeral: Content of a specific YouTube video, meeting recoding or PDF document (about 1/3 of these projects use PDF as the primary input format.)
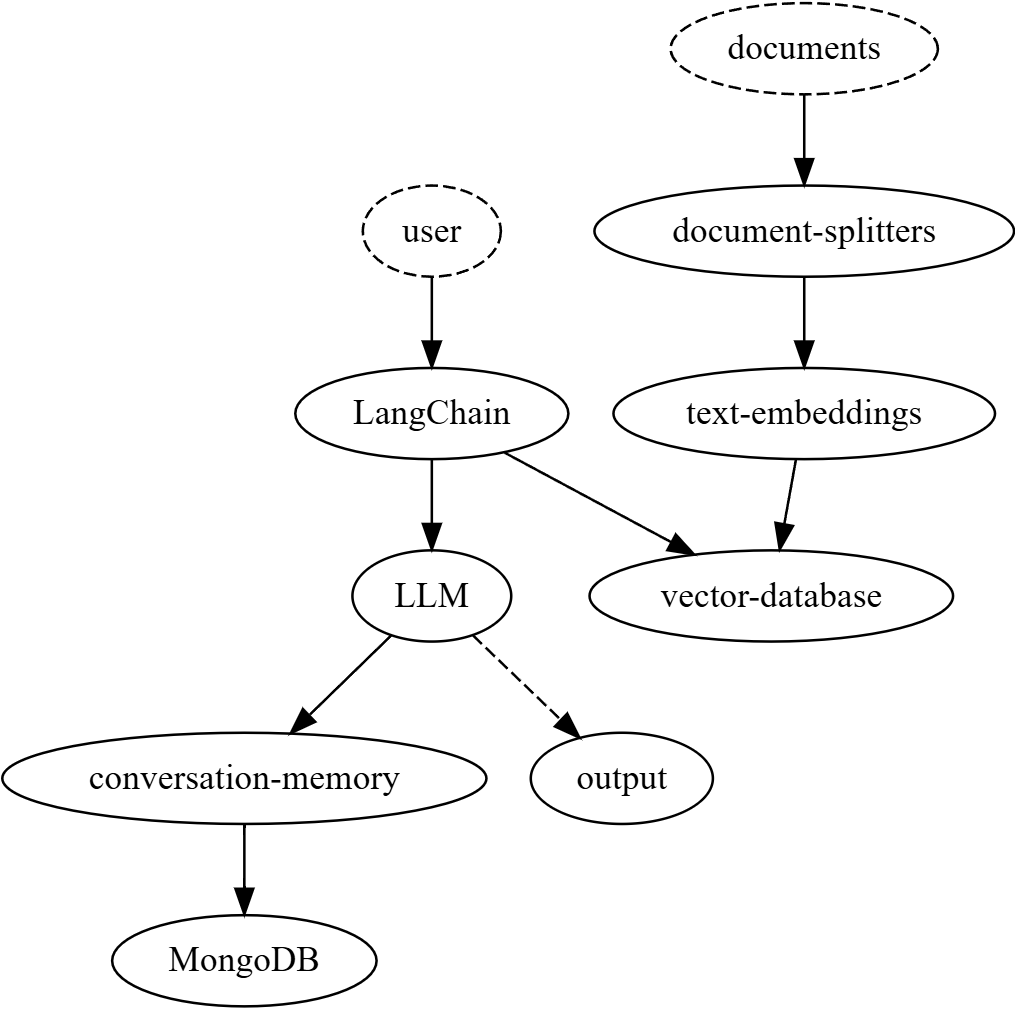
The universal complaint here is: RAG solutions are unreliable at every stage — indexing, retrieval, and generation. They're also hard to configure and debug.
An illustrative quote:
I posted about our RAG solution a month ago and got roasted all over Reddit, ...
The feedback from the community was tough, but we needed to hear it and have moved fast on a ton of changes.
The first feedback theme: *it is n8n + magicui components, am i missing anything?*
Next piece of feedback we needed to hear: *Don't make me RTFM.... Once you sign up you are dumped directly into the workflow screen, maybe add a interactive guide? Also add some example workflows I can add to my workspace?*
Also: *The deciding factor of which RAG solution people will choose is how accurate and reliable it is, not cost.*
The other key element is integration with external API (for web search and conversational UI).
There are also many elements of optional scaffolding: like hallucination detection, persistent memory, and voice wrappers.
Some examples from the wild:
Class 2: Business Process Automation (~25% of projects)
These projects automate business workflows: meeting notes, CRM lead scoring, resume matching, automated news analysis. They often process data in batches rather than responding to real-time queries.
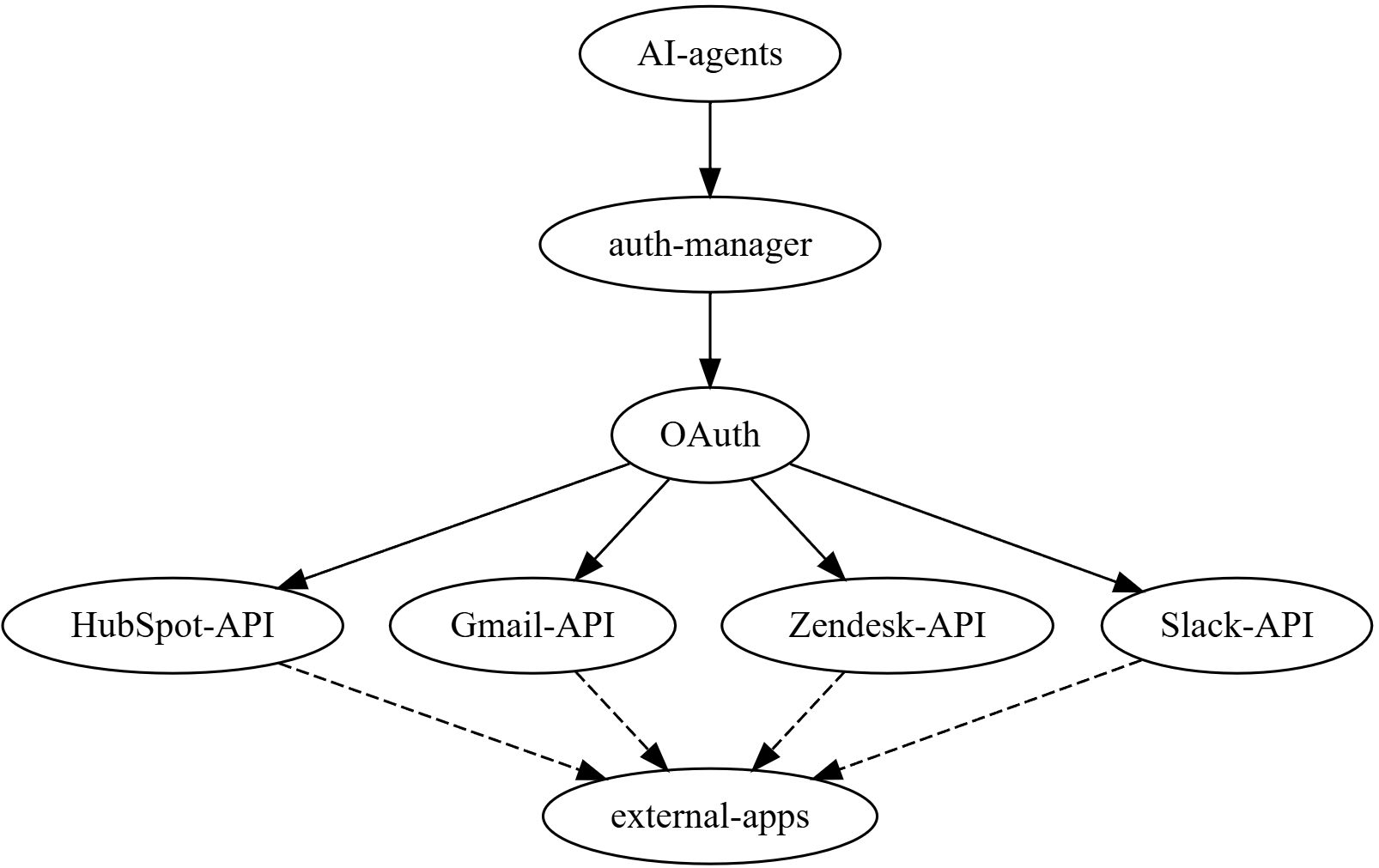
The critical pain here is the infrastructure. Engineers need a way to integrate their agents with a lot of different internal and external tools and services. They also need a reliable way to run the processes on schedule and/or on events.
Another illustrative quote:
What we didn't expect was just how much infra work that would require.
We ended up:
...
Writing custom integrations for Slack/GitHub/Notion. We used LlamaHub here for the actual querying, although some parts were a bit unmaintained and we had to fork + fix. We could've used Nango or Airbyte tbh but eventually didn't do that.Building an auto-refresh pipeline to sync data every few hours and do diffs based on timestamps. This was pretty hard as well.
Handling security and privacy (most customers needed to keep data in their own environments).
Handling scale - some orgs had hundreds of thousands of documents across different tools.
It became clear we were spending a lot more time on data infrastructure than on the actual agent logic. I think it might be ok for a company that interacts with customers' data, but definitely we felt like we were dealing with a lot of non-core work.
Some examples:
Class 3: Tool-Assisted Planning Agents (~15% of projects)
This includes multi-agent frameworks (most just don't work), research agents, coding agents, and ReAct-based systems for specific domains like Blender scripting or Kubernetes management.
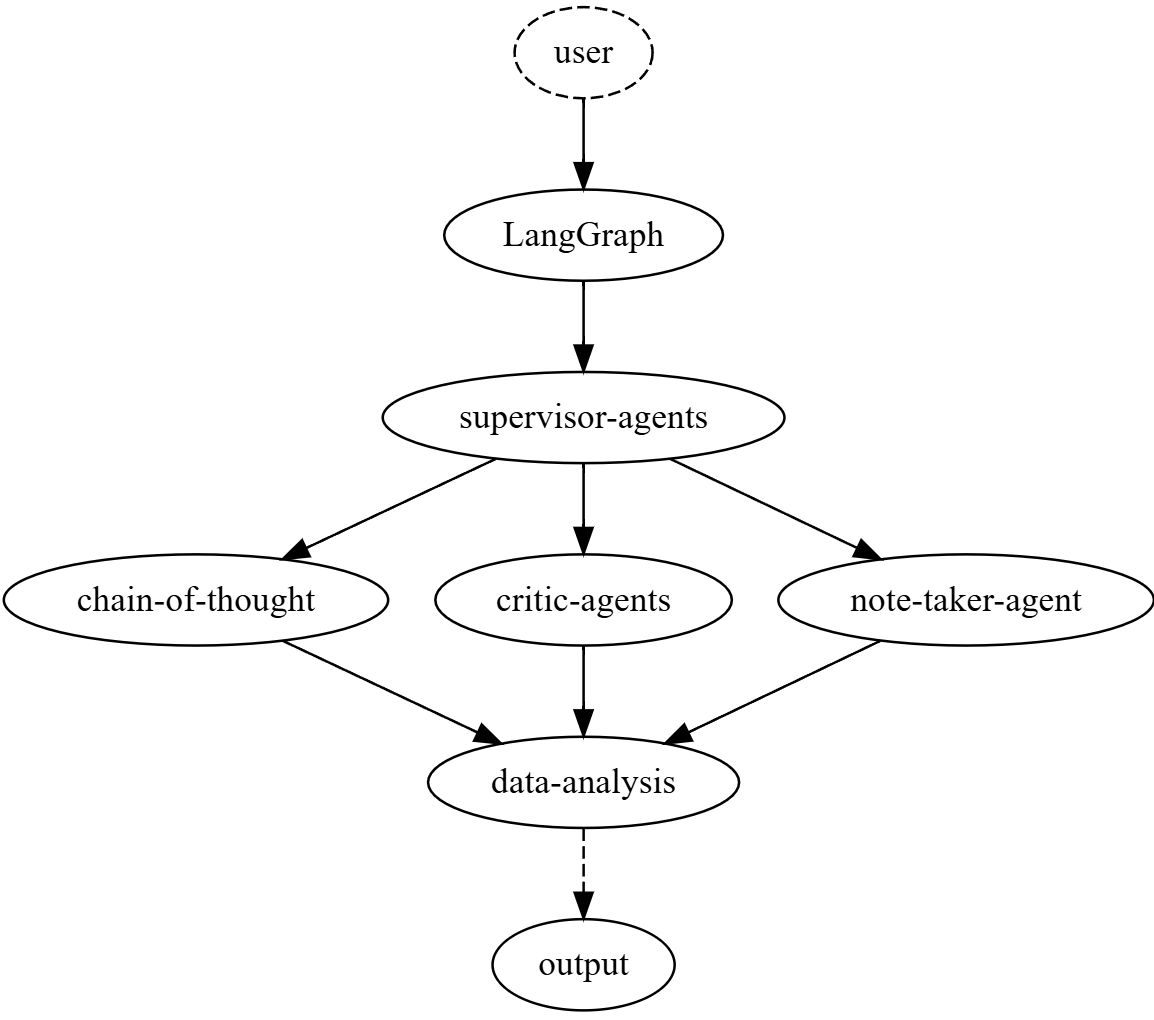
The key issue here is the reliability and reproducibility nightmare: Agentic runs with tools are unstable and nearly impossible to debug. Multi-agent setups amplify these problems exponentially.
From a developer struggling with ReAct:
I've created my tools with the Tool class, and tried with different queries explicitely designed to use several of them in the same process, but I keep getting my agent to stop its output after using the first tool.
For example, if I ask it to first look for people with experience in Hadoop and then calculate for each of them how many years of experience they have in the field (I have a tool designed for basic info search and one designed for calculating periods of time), it will output a list with an answer to the first question, but will forget the second one.
As I mentioned in my recent 6-months forecast for the AI industry, it feels like the most important topics for the close future of agentic systems are observability, explainability, reliability and traceability of agentic runs.
Examples:
The Infrastructure Gap
What struck me most wasn't the diversity of projects, but how similar their infrastructure needs are. Three distinct problem classes, but they all hit the same walls:
everyone reinvents the wheel connecting to popular services or building job scheduling systems
agents' behavior is often unpredictable; current tooling doesn't help too much
when things break, developers are flying blind
Reddit posts reveal a sad pattern: developers start excited about the AI capabilities, then spend 80% of their time on boring infrastructure work that has nothing to do with their core idea.
The real bottlenecks aren't only model capabilities; they're also infrastructure reliability and developer experience. The projects that solve these problems might be the most valuable.
Again, I encourage to play with the data yourself. Although, these patterns seem remarkably consistent with my own experience building agent systems — I'd love to hear if others see different patterns in their work.